
Neural Predictions of Others’ Beliefs
Post by Elisa Guma
What's the science?
Humans are able to form detailed representations of others’ thoughts and beliefs that are distinct from their own. This capacity, often referred to as theory of mind, is critical to our social behaviour and ability to interact with others. While a number of brain areas, including the temporal-parietal junction, superior temporal sulcus, and dorsal medial prefrontal cortex, have been shown to support social reasoning, little is known about the mechanisms underlying theory of mind at the neuronal level. This week in Nature, Jamali and colleagues use single neuron recordings from the human dorsomedial prefrontal cortex during behavioural tasks to understand how these cells support theory of mind.
How did they do it?
The authors used custom-made, multi-electrode arrays to record neuronal activity from 324 neurons in the dorsomedial prefrontal cortex of 15 participants as they performed an auditory version of a common theory of mind task: the false-belief task. Participants were patients undergoing surgery unrelated to study participation.
During the behavioural task, participants were presented with a series of unique narratives describing simple events, paired with questions about the events that tested their knowledge about another’s belief. For example, the narrative could be: “You and Tom see a jar on the table. After Tom leaves, you move the jar to the cupboard,” followed by the question “Where does Tom believe the jar is?”. In addition to this scenario, considered a false-belief trial (i.e. the other’s belief is different than reality), participants were presented with true-belief trials, in which the other’s belief is the same as reality (i.e. leaving the jar on the table while Tom is away). To distinguish self-from other-belief representations in the brain, participants were also given trials in which their own imagined belief had to be judged as true or false. In addition to the scenario described above, a number of others were focused on another's beliefs of objects (e.g. table), containers (e.g. cupboard), foods (e.g. vegetables), places (e.g. park), animals (e.g. cat), and appearance (e.g. colour red).
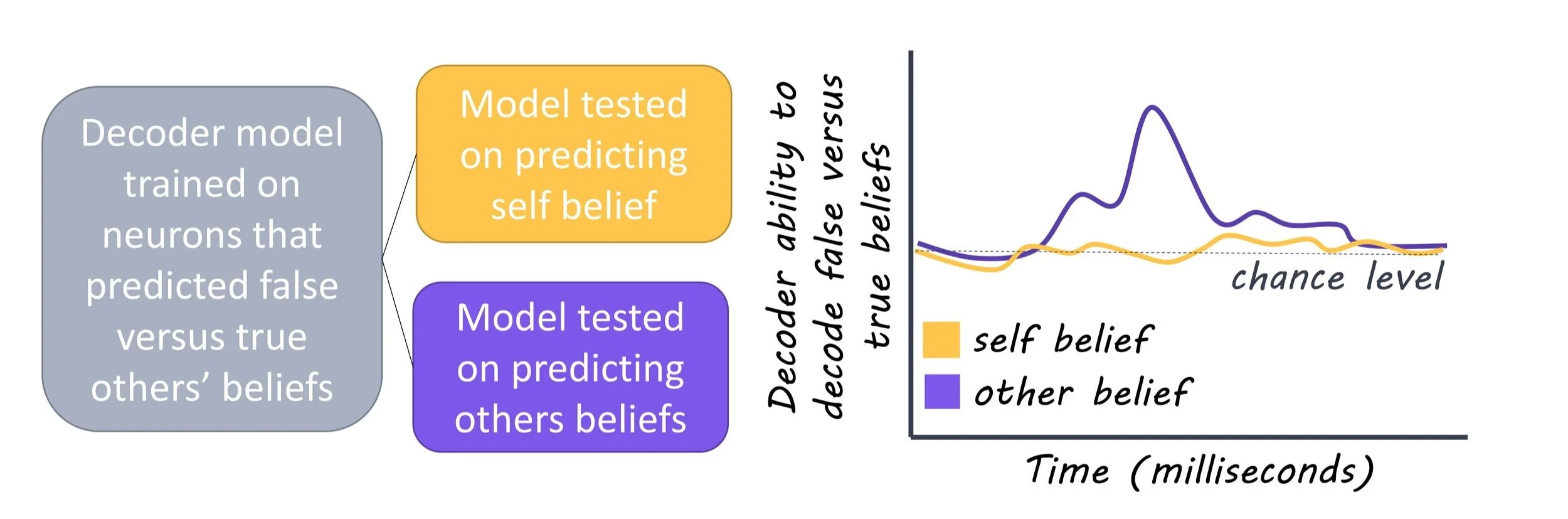
Following the alignment of trial events with neural activity, the authors used linear models that quantified whether and to what degree the activity of each recorded neuron could predict the specific trial condition (i.e. to distinguish between true- and false-belief trials or related to objects vs. non-objects) during questioning. Neuronal data were randomly divided into two subsets. One subset consisted of 80% of the trials and was used to train the model to predict the trial condition. Next, the other subset was used to test the accuracy of the model’s predictions on fresh data.
What did they find?
The authors found that many neurons (20%) in the dorsomedial prefrontal cortex responded selectively when considering another’s beliefs. Further, they found that 23% of neurons accurately predicted whether the other's beliefs were true or false. These neurons were distinct from those activated (27%) when participants had to determine whether their own imagined beliefs were true or false, confirming that a distinct class of neurons encodes and predicts beliefs other than our own. Finally, the authors observed differences in the neuronal populations activated based on the contents of the others’ beliefs (i.e. object, place, food, etc). These data indicate that these neurons encoded highly detailed information about the others’ beliefs and suggest that in order to accurately infer the beliefs of others, it is important to determine whether the beliefs are true or false as well as the specific beliefs being considered.
What's the impact?
By leveraging single cell recordings in the human dorsomedial prefrontal cortex, the authors identified neurons that encode information about others’ beliefs, distinct from their own beliefs, across richly varying scenarios. They show that there is high specificity between cells based on the content of the others’ beliefs and that they are able to accurately predict whether these beliefs are true or false. These findings provide great insight into the cellular underpinnings of how the human brain is able to represent others’ beliefs. Future work may investigate whether these neurons are affected in individuals with psychiatric disorders known to affect social cognition and theory of mind.

Jamali et al. Single-neuronal predictions of others’ beliefs in humans. Nature (2021). Access to the original publication can be found here.


